Why DSV Exists
DSV is not the first scalability upgrade in Powerloom. It is the decentralization of the upgrade that came before it.
Implementation: powerloom/snapshot-sequencer-validator
The protocol evolved in three distinct steps:
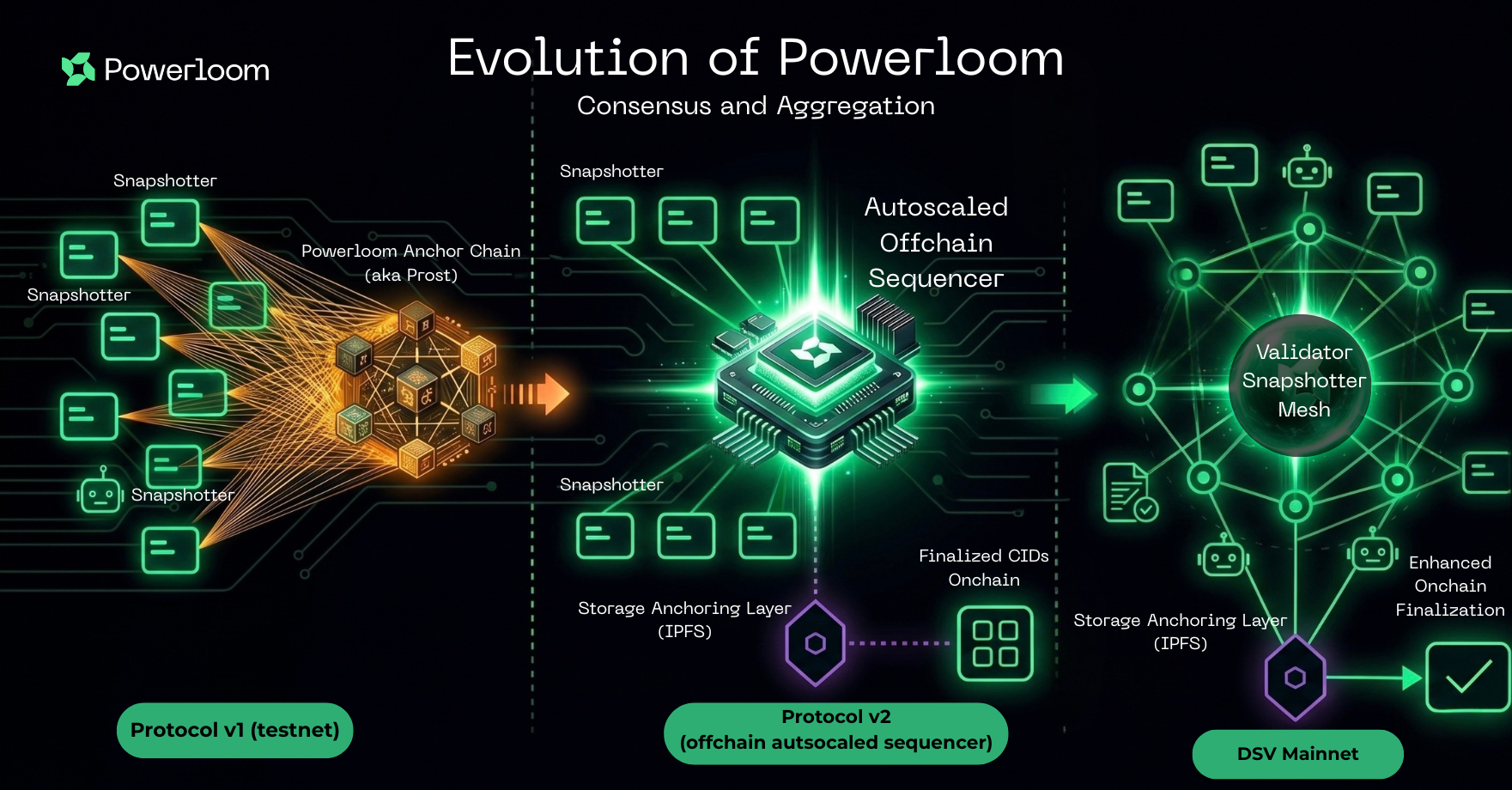
- Protocol v1 relied on direct snapshot-submission transactions against protocol state.
- Protocol v2 replaced that with a centralized off-chain sequencer that batched submissions, uploaded batch payloads to IPFS, and anchored finalized results on-chain.
- DSV replaces that centralized sequencer model with a decentralized sequencer-validator network.
That distinction matters because the problem DSV solves is not the same problem Protocol v2 solved.
What Protocol v2 solved
Protocol v2 was the major architectural break from the older testnet model.
It replaced the expensive and operationally fragile pattern where every snapshot submission needed to become its own on-chain transaction. Instead, the protocol moved to:
- an off-chain sequencer,
- batch construction and IPFS upload,
- on-chain anchoring of finalized batch outputs,
- and validator attestation over those batch submissions.
That was a substantial performance upgrade. It is the reason the protocol could move away from the earlier per-submission on-chain path and support much higher throughput.
The public Protocol v2 overview already documents the pressures that made that upgrade necessary:
- Powerloom was operating at more than 1 million snapshot submission transactions per day.
- At that scale, the older relayer-driven submission flow saw more than 5% of transactions dropped in stressed periods.
Why Protocol v2 was not the end state
Protocol v2 solved throughput, but it still concentrated sequencing responsibility into a centralized, monolithic service.
That created a different class of constraints:
- the sequencer remained a single operational dependency,
- the Powerloom Foundation remained responsible for running and maintaining that system,
- and even one new data market could require non-trivial sequencing-side configuration and operational intervention.
In other words, Protocol v2 improved performance, but it did not yet decentralize the responsibility for finalization.
That is the gap DSV closes.
What changed with DSV
DSV keeps the core direction introduced by Protocol v2, but replaces the centralized sequencer model with a validator mesh that separates data propagation, batch consensus, and on-chain anchoring across multiple network participants:
- Snapshotters continue building market-specific snapshots.
- The local collector pushes those submissions into a libp2p mesh instead of routing them into one centralized sequencer service.
- Validator nodes collect, validate, deduplicate, and aggregate submissions off-chain.
- Consensus output is uploaded to IPFS and only the final canonical references are anchored on-chain.
The architectural objective is different from the one Protocol v2 served:
- Protocol v2 made high-throughput finalization operationally feasible.
- DSV makes that finalization model decentralized, fault-tolerant, and less dependent on one Foundation-maintained service boundary.
Why this is a continuation of Protocol v2
DSV is not a separate protocol. It is the continuation of the same design direction introduced in Protocol v2:
- batched submissions instead of per-snapshot chain writes,
- off-chain aggregation before on-chain anchoring,
- IPFS-backed batch payloads, and
- smart-contract state designed around finalized outputs rather than raw transport.
The key difference is organizational and architectural at the same time: where Protocol v2 depended on a centralized sequencer run as a monolithic service, DSV distributes sequencing, aggregation, and submission responsibility across a validator network.
What DSV optimizes for
DSV is opinionated about the problem it is solving. It is built to support:
- continuous epoch releases for fast-moving markets,
- majority-based agreement over per-project snapshot CIDs,
- verifiable finalization through on-chain contract state, and
- data reuse so later compute modules can build on prior finalized outputs.
Where DSV sits relative to adjacent systems
DSV is not trying to collapse every data category into one protocol.
- Compared with indexing networks, DSV is oriented around finalized per-epoch outputs that can be verified back to contract state, rather than flexible historical query execution over an indexed schema.
- Compared with oracle feeds, DSV is designed for broader data-market outputs and reusable snapshot datasets, not only narrow reference-feed delivery.
- Compared with centralized APIs, DSV keeps the product surface simple to consume while preserving an independent provenance check through
ProtocolState.maxSnapshotsCid(...).
This is the practical distinction that matters for Powerloom: DSV is a data-finalization system whose outputs can be consumed directly by products and agents without reducing trust to the operator serving the API.
That is why the rest of this section goes deeper than a high-level overview. The architectural value only becomes clear when you can trace the full path from snapshot build to an independently verifiable finalized CID.