Snapshot Generation
Snapshot Computation Modules
As briefly introduced in the section on Snapshotter architecture, compute modules are pulled into the node runtime by setup scripts and are specified in the configuration for project types under the key processor.
https://github.com/powerloom/snapshotter-configs/blob/39e4713cdd96fff99d100f1dea7fb7332df9e491/projects.example.json#L15-L28
Let's take the example of the snapshot builder configured for the project type zkevm:owlto_bridge and locate it in the snapshotter-computes repo, in the zkevm_quests branch
https://github.com/powerloom/snapshotter-computes/blob/29199feab449ad0361b5867efcaae9854992966f/owlto_bridge.py#L1-L31
As observed, it implements the compute() interface expected from Snapshotter implementations inheriting GenericProcessorSnapshot.
https://github.com/powerloom/pooler/blob/634610801a7fcbd8d863f2e72a04aa8204d27d03/snapshotter/utils/callback_helpers.py#L179-L196
Base Snapshots
Callback workers calculate base snapshots against an epochId, corresponding to collections of state observations and event logs between the blocks at heights in the range begin, end. They invoke the use case-specific computation logic as configured in the computation modules section.
The data sources are specified against the projects key in the configuration shown in the section above.
Data Source Specification: Non-bulk Mode
- If
bulk_modeis set toFalseand an empty array is assigned to theprojects:
The Snapshotter node attempts to retrieve data sources corresponding to the projects key from the protocol state.
https://github.com/powerloom/pooler/blob/634610801a7fcbd8d863f2e72a04aa8204d27d03/snapshotter/processor_distributor.py#L321-L332
- If the
projectskey is non-existent- data sources can also be dynamically added on the protocol state contract which the processor distributor syncs with
https://github.com/powerloom/pooler/blob/634610801a7fcbd8d863f2e72a04aa8204d27d03/snapshotter/processor_distributor.py#L738-L751
- Else, we can have a static list of contracts
Data Source Specification: Bulk Mode
- If
bulk_modeis set totrue:
In this case, the projects key is not checked by the snapshotter and is usually left as an empty array.
Bulk Mode is highly effective in situations where:
- The list of data sources to be tracked is continually expanding, or
- Snapshots don't need to be submitted for every epoch for all the data sources because:
- The state change between epochs may not be of interest.
- Once a certain state change is observed, no further changes need to be recorded. Example use cases include monitoring on-chain activities and tracking task or quest completion statuses on the blockchain.
https://github.com/powerloom/snapshotter-configs/blob/39e4713cdd96fff99d100f1dea7fb7332df9e491/projects.example.json#L17-L27
This allows for flexibility to filter through all transactions and blocks without the need for predefined data sources.
The Processor Distributor generates a SnapshotProcessMessage with bulk mode enabled for each project type. When snapshot workers receive this message, they leverage common preloaders to filter out relevant data.
https://github.com/powerloom/pooler/blob/634610801a7fcbd8d863f2e72a04aa8204d27d03/snapshotter/processor_distributor.py#L717-L730
Since common datapoints like block details, transaction receipts, etc., are preloaded, this approach can efficiently scale to accommodate a large number of project types with little to no increase in RPC (Remote Procedure Call) calls.
Whenever a data source is added or removed by the signaling ecosystem, the protocol state smart contract emits a ProjectUpdated event with the following data model.
https://github.com/powerloom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/models/data_models.py#L102-L105
Format of specifying data sources against projects
- EVM-compatible wallet address strings
"<addr1>_<addr2>"strings that denote the relationship between two EVM addresses (for eg ERC20 balance ofaddr2against a token contractaddr1)
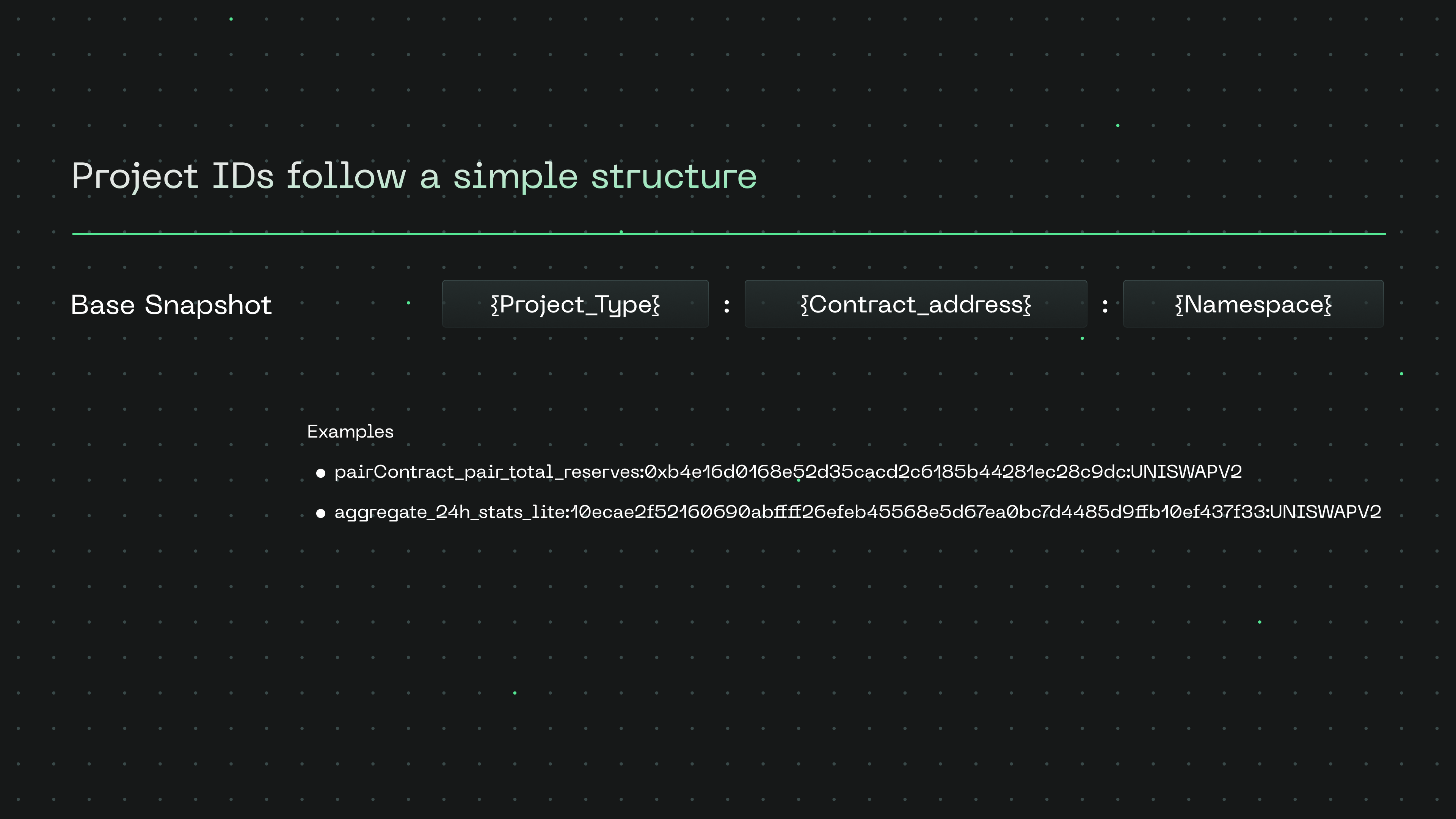
Project ID generation
https://github.com/powerloom/pooler/blob/634610801a7fcbd8d863f2e72a04aa8204d27d03/snapshotter/utils/snapshot_worker.py#L51-L71
Example of snapshot computation
Base snapshot of trade events:
https://github.com/powerloom/snapshotter-computes/blob/6fb98b1bbc22be8b5aba8bdc860004d35786f4df/trade_volume.py#L14-L44
Aggregate Snapshots
Aggregate and higher-order snapshots that build on base snapshots are configured in market-specific repositories. This is where you can observe the dependency graph of snapshot composition in action.
The order and dependencies of these compositions are specified according to the aggregate_on key.
SingleProject aggregation type
https://github.com/powerloom/snapshotter-configs/blob/fcf9b852bac9694258d7afcd8beeaa4cf961c65f/aggregator.example.json#L1-L10
- This type specifies the generation of an aggregation snapshot for a single project across a span of epochs relative to the current
epochId.- The
filters.projectIdkey specifies the substring that should be contained within a project ID on which the base snapshot computation is completed for the epoch. - For example, a base snapshot built on a project ID like
pairContract_trade_volume:0xb4e16d0168e52d35cacd2c6185b44281ec28c9dc:UNISWAPV2triggers the workerAggregateTradeVolumeProcessoras defined in theprocessorconfig, against the pair contract0xb4e16d0168e52d35cacd2c6185b44281ec28c9dc.
- The
- The span of epochs on which corresponding base snapshots will be aggregated is determined by the logic contained in the module specified in the
processorkey.
The following implementation aggregates trade volume snapshots across a span of 24 hours worth of epochs, if available. Otherwise, it aggregates the entire span of epochs available on the protocol against the data market and reports it back.
https://github.com/powerloom/snapshotter-computes/blob/6fb98b1bbc22be8b5aba8bdc860004d35786f4df/aggregate/single_uniswap_trade_volume_24h.py#L110-L121
MultiProject aggregation type
https://github.com/powerloom/snapshotter-configs/blob/fcf9b852bac9694258d7afcd8beeaa4cf961c65f/aggregator.example.json#L25-L31
projects_to_wait_forspecifies the exact project IDs on which this higher-order aggregation will be generated.- The aggregation snapshot build for this is triggered once a snapshot build has been achieved for an
epochId.
The configuration above generates a dataset that can be further used to render a dashboard containing trade information across a large number of Uniswap V2 pair contracts.
Project ID Generation
In the case of 'MultiProject` aggregations, their project IDs are generated with a combination of the hash of the dependee project IDs along with the namespace and project type string.

The following is the section where the relevant project IDs are generated according to their configuration type.
https://github.com/powerloom/pooler/blob/d8b7be32ad329e8dcf0a7e5c1b27862894bc990a/snapshotter/utils/aggregation_worker.py#L59-L92