Sequencer Overview
Sequencer
This page describes the Protocol v2 sequencer model. For the live DSV mainnet flow, including two-level validator aggregation and VPA-based submission, see Protocol Workflow and Roles and Topology.
The sequencer listening interfaces for specific data markets are listed in the following trusted sequencer JSON file hosted on the Powerloom Github repository:
DO NOT attempt to connect to any other sequencer interfaces supplied by anyone claiming to represent Powerloom if they are not listed in the above file.
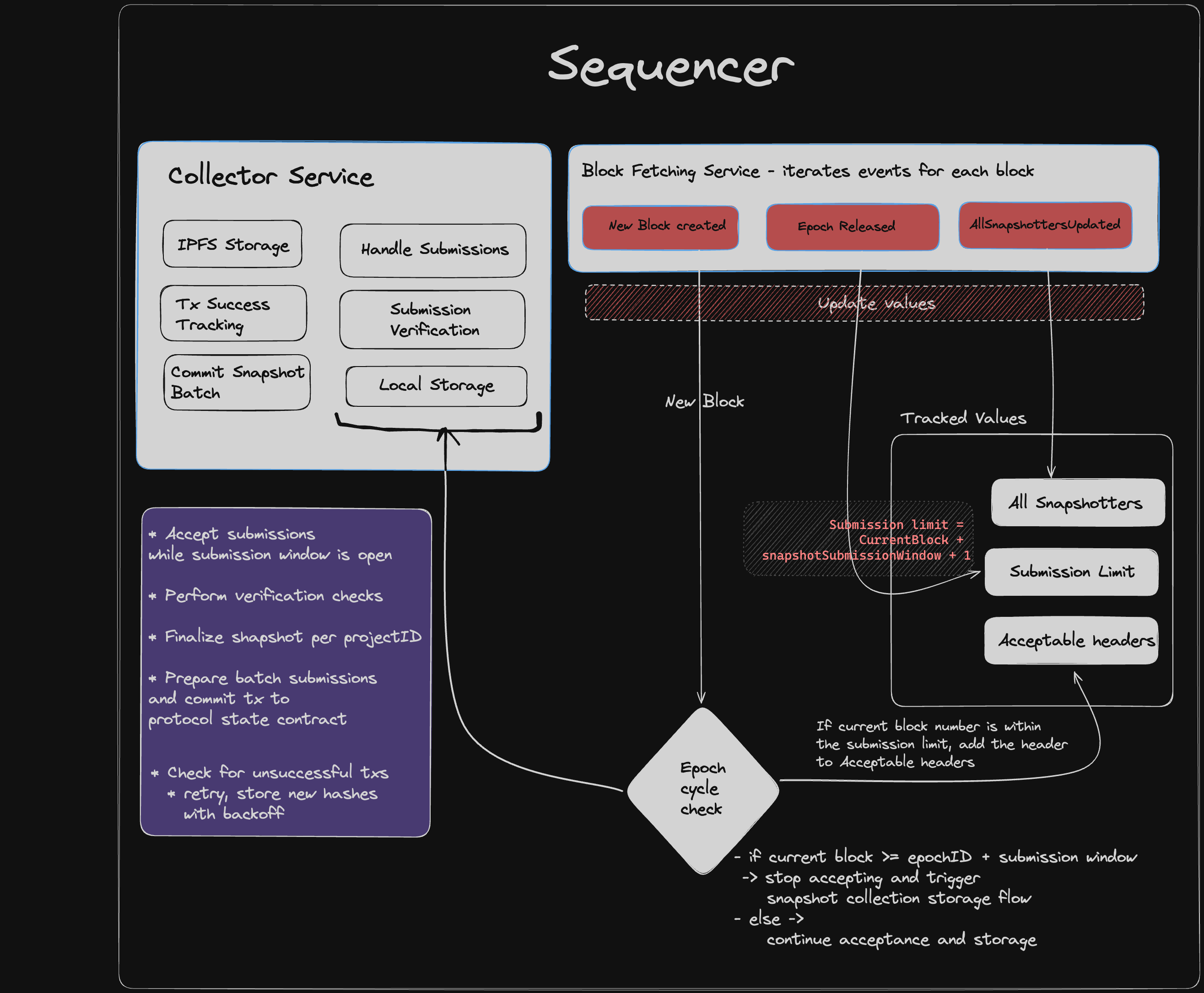
The sequencer has the following primary functions:
-
Snapshot Collection: Receive snapshot submissions per epoch across project IDs from all participating snapshotters in a data market. Read more in the following section.
-
Snapshot Finalization: Finalize snapshot submission for each project ID according to consensus rules
-
Batch Upload Snapshot Submissions: Create multiple batches of datasets of snapshot submissions and finalized CIDs across project IDs within an epoch.
-
Anchor Proof of Batch: Upload these batches to IPFS or a decentralized storage layer. Commit the storage identifier to the protocol state smart contract for validators and other peers to reference for subsequent workflows according to their roles.
Snapshot collection and finalization
The sequencer maintains an internal clock corresponding to the release and end of the submission window for an epoch. It receives snapshot submissions from snapshotter peers over libp2p streams.
It also performs important verification checks:
- identity verification by referencing an EIP-712 signature field contained within the submission payloads against the snapshotter identities allowed for a data market on the protocol state smart contract
- submission window verification check by referencing the protocol state head block number as attached in the header of the submission sent by a snapshotter peer
- DDoS protection that checks the number and frequency of submissions received from a snapshotter peer per epoch
As the submission window for an epoch closes, the finalized submission for each project ID is decided upon by the sequencer according to rules of consensus, out of all the submissions sent out by participating snapshotter peers.
Batch upload and anchor proof
Multiple such finalizations are decided upon all project IDs within a data market and they are batched together in multiple datasets, if required, at the end of every epoch's submission window. These datasets are then uploaded to IPFS or a decentralized storage layer, and references to their storage (for eg, a content identifier aka CID) are committed to the protocol state smart contract.
The finalized snapshot submissions for all corresponding project IDs are placed in an 'intermediate' finalized state on the protocol state. They can be considered to be trusted, but are awaiting attestation from validators that participate in the protocol.
Read more on how validators submit attestations on intermediate finalized states.
Batches contain submission details for multiple project IDs with the following information per project:
- Submission objects from snapshotter peers that contain their respectively signed EIP-712 objects
- Finalized snapshot as reported by sequencer
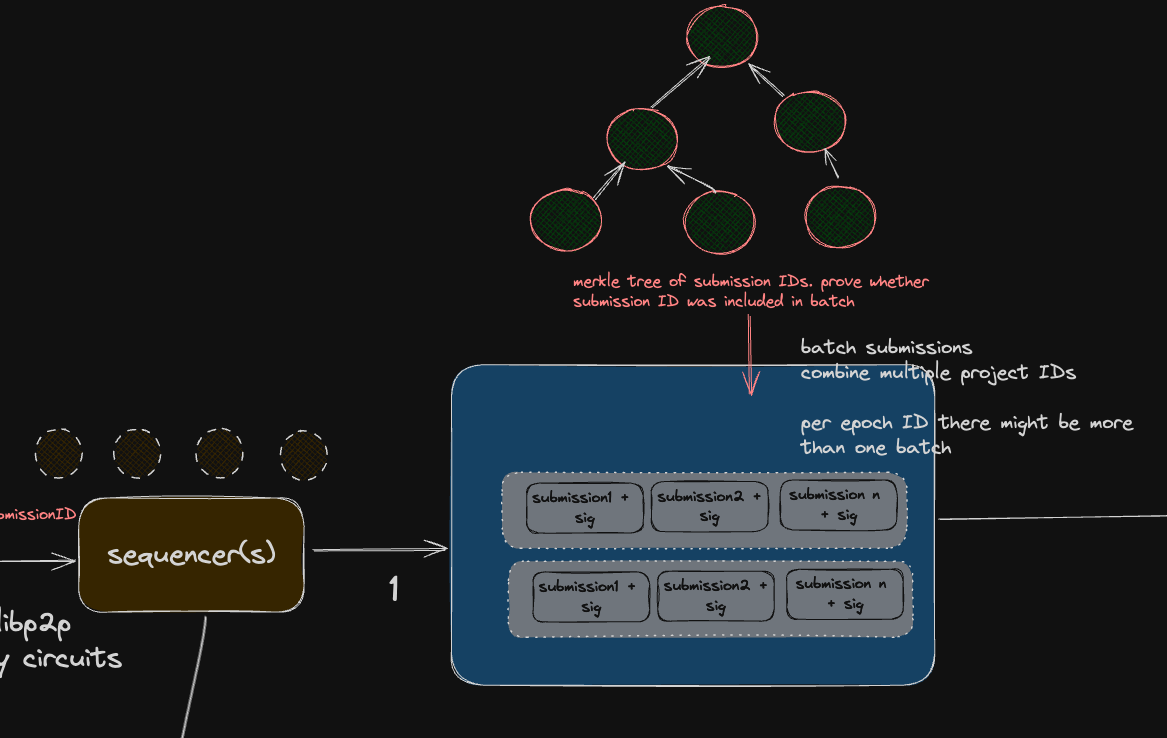
Batch upload integrity: Roothash of Merkle tree of finalized CIDs
Taking a look at the method submitSubmissionBatch in the protocol state contract, we see that it contains the root hash of a Merkle tree constructed out of the finalized CIDs of the project IDs in the order included in the batch.
function submitSubmissionBatch(
string memory batchCid,
uint256 epochId,
string[] memory projectIds,
string[] memory snapshotCids,
bytes32 finalizedCidsRootHash
) public onlySequencer
The root hash of the Merkle tree of finalized CIDs is used to verify the integrity of the batch upload by the validator peers.
- See also: Structure of a batch
Batch upload integrity:Roothash of Merkle tree of submission IDs
An important feature of each batch is that the dataset against it contains the root hash of a Merkle tree constructed out of the submission IDs sent out by the snapshotter peers. Utilizing this, snapshotter peers can verify whether their submissions were included in batches committed to the protocol state smart contract for an epoch.
The submission IDs contained in a batch are added to the leaves of the Merkle tree as determined by the lexicographical ordering of their corresponding project IDs.
Each batch's Merkle tree builds on the tree from the preceding batch within the same epoch.
Sequencer Deployment: Decoupled Architecture
The sequencer is in practice comprised of several moving parts that are deployed in a Kubernetes orchestration environment.
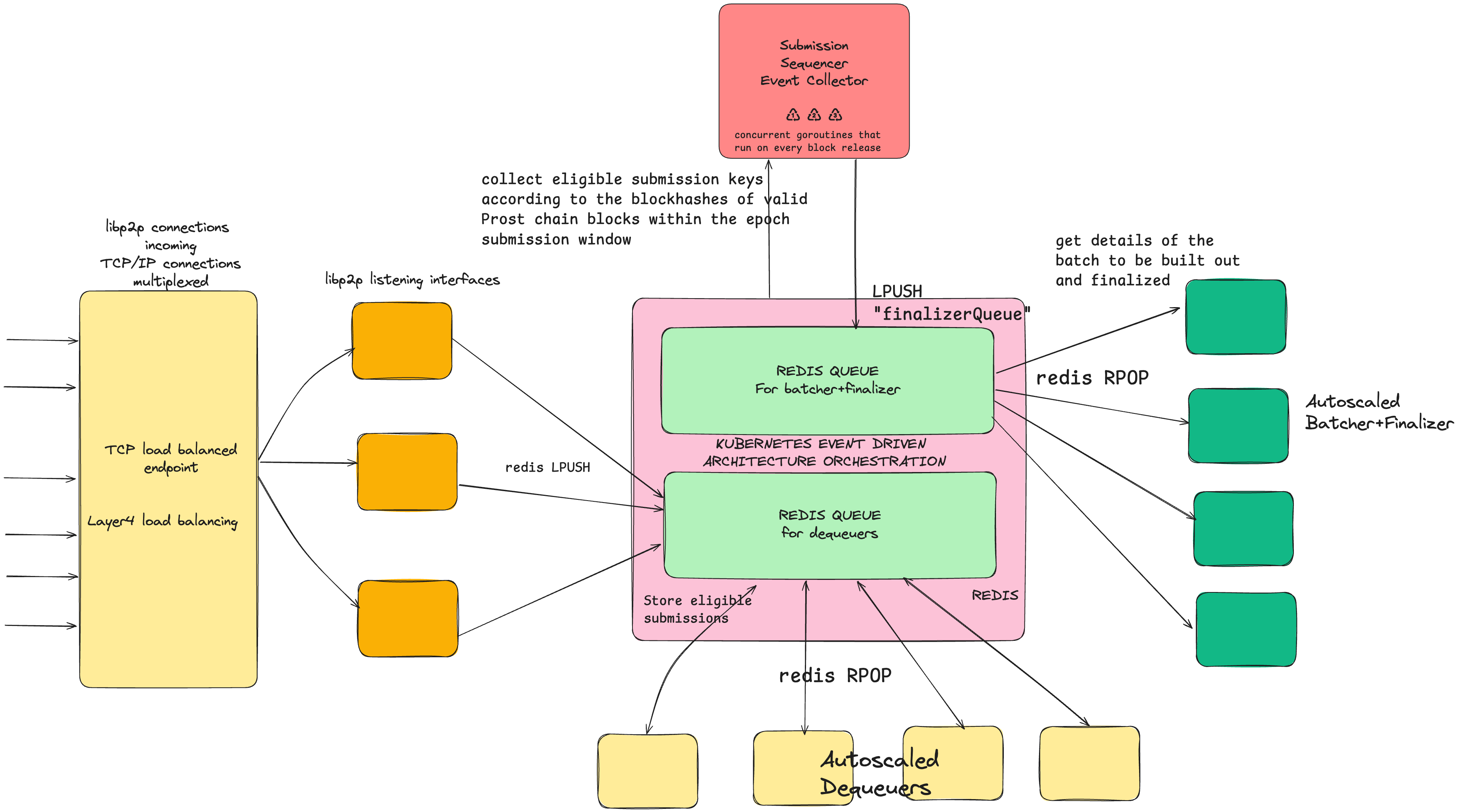
Loadbalanced libp2p listener
The libp2p listening interface is loadbalanced on Layer 4 of the networking stack (TCP/IP load balancing) by a Kubernetes service. These have inbuilt DDoS protection and further push workloads downstream to dequeuer pods.
- Read more: Sequencer: Libp2p Listener
- Github
Autoscaled dequeuers
These dequeuers are autoscaled by an event driven architecture and intermediated by worker queues that can work on varied backends, for eg. Redis (for demonstration purposes) or Kafka.
- Read more: Sequencer: Dequeuer
- Github
Event collector
This works as the system clock of the sequencer setup as a whole.
- It keeps up with the head of the Powerloom chain,
- Tracks epoch releases
- Maintains important state information regarding time windows for
- snapshot submission
- snapshot collection into batches
- Distribution of batch finalization to finalizers
- attestation submission
- Read more: Sequencer: Event Collector
- Github
Autsocaled Batch Finalizers
These are another set of autoscaled pods that are responsible for
- finalizing the snapshot submissions for each project ID.
- uploading the batches to IPFS or a decentralized storage layer.
- committing the storage references to the protocol state smart contract.
- Read more: Sequencer: Batch Finalizer
- Github